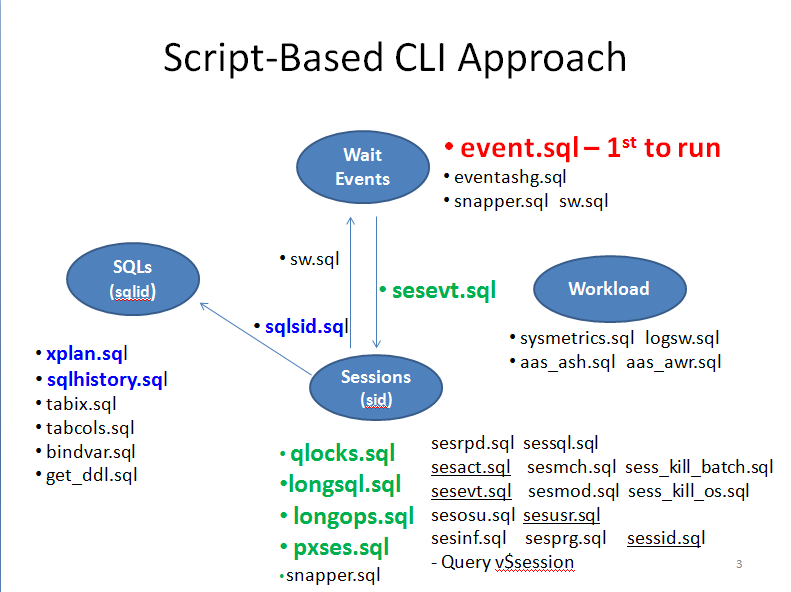
Plan hash value: 4161037915 -------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers | Reads | Writes | OMem | 1Mem | Used-Mem | Used-Tmp| -------------------------------------------------------------------------------------------------------------------------------------------- ------------------------------------------ | 1 | SORT ORDER BY | | 1 | 1 | 113K|00:02:27.54 | 4242K| 12873 | 8580 | 76M| 3013K| 67M (0)| | | 2 | HASH UNIQUE | | 1 | 1 | 113K|00:02:23.74 | 4242K| 12873 | 8580 | 72M| 7323K| 9538K (1)| 73728 | |* 3 | FILTER | | 1 | | 114K|00:03:25.41 | 4242K| 4293 | 0 | | | | | | 4 | NESTED LOOPS | | 1 | 1 | 114K|00:00:15.77 | 4239K| 4291 | 0 | | | | | | 5 | MERGE JOIN CARTESIAN | | 1 | 1 | 199K|00:00:01.71 | 6001 | 123 | 0 | | | | | | 6 | MERGE JOIN CARTESIAN | | 1 | 1 | 7112 |00:00:00.44 | 5998 | 123 | 0 | | | | | |* 7 | HASH JOIN OUTER | | 1 | 1 | 889 |00:00:00.15 | 5995 | 123 | 0 | 985K| 927K| 1229K (0)| | | 8 | NESTED LOOPS | | 1 | 1 | 889 |00:00:00.11 | 5979 | 123 | 0 | | | | | | 9 | NESTED LOOPS | | 1 | 1 | 889 |00:00:00.10 | 5088 | 123 | 0 | | | | | |* 10 | HASH JOIN OUTER | | 1 | 1 | 889 |00:00:00.09 | 4197 | 123 | 0 | 928K| 928K| 1265K (0)| | | 11 | NESTED LOOPS | | 1 | 1 | 865 |00:00:00.10 | 4193 | 123 | 0 | | | | | | 12 | NESTED LOOPS | | 1 | 1 | 1839 |00:00:00.07 | 504 | 123 | 0 | | | | | | 13 | MERGE JOIN CARTESIAN | | 1 | 1 | 1 |00:00:00.01 | 12 | 0 | 0 | | | | | | 14 | NESTED LOOPS | | 1 | 1 | 1 |00:00:00.01 | 8 | 0 | 0 | | | | | | 15 | NESTED LOOPS | | 1 | 1 | 1 |00:00:00.01 | 5 | 0 | 0 | | | | | | 16 | TABLE ACCESS BY INDEX ROWID| OZBJZFDS | 1 | 1 | 1 |00:00:00.01 | 3 | 0 | 0 | | | | | |* 17 | INDEX UNIQUE SCAN | PK_OZBJZFDS | 1 | 1 | 1 |00:00:00.01 | 2 | 0 | 0 | | | | | | 18 | TABLE ACCESS BY INDEX ROWID| OZBJZFD_CATEGORY | 1 | 26 | 1 |00:00:00.01 | 2 | 0 | 0 | | | | | |* 19 | INDEX UNIQUE SCAN | PK_OZBJZFD_CATEGORY | 1 | 1 | 1 |00:00:00.01 | 1 | 0 | 0 | | | | | |* 20 | TABLE ACCESS BY INDEX ROWID | OZBJZFD_MARKETS | 1 | 1 | 1 |00:00:00.01 | 3 | 0 | 0 | | | | | |* 21 | INDEX RANGE SCAN | PK_OZBJZFD_MARKETS | 1 | 1 | 1 |00:00:00.01 | 2 | 0 | 0 | | | | | | 22 | BUFFER SORT | | 1 | 1 | 1 |00:00:00.01 | 4 | 0 | 0 | 2048 | 2048 | 2048 (0)| | |* 23 | TABLE ACCESS BY INDEX ROWID | MARKETS | 1 | 1 | 1 |00:00:00.01 | 4 | 0 | 0 | | | | | |* 24 | INDEX RANGE SCAN | PK_MARKETS | 1 | 1 | 1 |00:00:00.01 | 2 | 0 | 0 | | | | | |* 25 | TABLE ACCESS BY INDEX ROWID | OZBJZFD_OQNCVDSS | 1 | 1 | 1839 |00:00:00.07 | 492 | 123 | 0 | | | | | |* 26 | INDEX RANGE SCAN | PK_OZBJZFD_OQNCVDSS | 1 | 1 | 1894 |00:00:00.01 | 16 | 13 | 0 | | | | | |* 27 | TABLE ACCESS BY INDEX ROWID | OQNCVDSS | 1839 | 1 | 865 |00:00:00.03 | 3689 | 0 | 0 | | | | | |* 28 | INDEX UNIQUE SCAN | PK_OQNCVDSS | 1839 | 1 | 1839 |00:00:00.01 | 1841 | 0 | 0 | | | | | | 29 | VIEW | | 1 | 29 | 29 |00:00:00.01 | 4 | 0 | 0 | | | | | | 30 | SORT UNIQUE | | 1 | 29 | 29 |00:00:00.01 | 4 | 0 | 0 | 4096 | 4096 | 4096 (0)| | | 31 | UNION-ALL | | 1 | | 29 |00:00:00.01 | 4 | 0 | 0 | | | | | | 32 | INDEX FULL SCAN | PK_SOURCE_TARGET_RULES | 1 | 20 | 20 |00:00:00.01 | 1 | 0 | 0 | | | | | | 33 | TABLE ACCESS FULL | CARRYOVER_ISOC_MAPPING | 1 | 9 | 9 |00:00:00.01 | 3 | 0 | 0 | | | | | | 34 | TABLE ACCESS BY INDEX ROWID | SPEED_CODES | 889 | 1 | 889 |00:00:00.01 | 891 | 0 | 0 | | | | | |* 35 | INDEX UNIQUE SCAN | PK_SPEED_CODES | 889 | 1 | 889 |00:00:00.01 | 2 | 0 | 0 | | | | | | 36 | TABLE ACCESS BY INDEX ROWID | OQNCVDS_TYPES | 889 | 1 | 889 |00:00:00.01 | 891 | 0 | 0 | | | | | |* 37 | INDEX UNIQUE SCAN | PK_OQNCVDS_TYPES | 889 | 1 | 889 |00:00:00.01 | 2 | 0 | 0 | | | | | | 38 | INDEX FAST FULL SCAN | PK_OFFER_PROD | 1 | 1255 | 1255 |00:00:00.01 | 16 | 0 | 0 | | | | | | 39 | BUFFER SORT | | 889 | 8 | 7112 |00:00:00.01 | 3 | 0 | 0 | 2048 | 2048 | 2048 (0)| | | 40 | TABLE ACCESS FULL | BILLING_FREQ | 1 | 8 | 8 |00:00:00.01 | 3 | 0 | 0 | | | | | | 41 | BUFFER SORT | | 7112 | 28 | 199K|00:00:00.20 | 3 | 0 | 0 | 2048 | 2048 | 2048 (0)| | | 42 | TABLE ACCESS FULL | UNIT_TYPES | 1 | 28 | 28 |00:00:00.01 | 3 | 0 | 0 | | | | | |* 43 | TABLE ACCESS BY INDEX ROWID | UHCDN_RATES | 199K| 1 | 114K|00:02:16.61 | 4233K| 4168 | 0 | | | | | |* 44 | INDEX RANGE SCAN | PK_UHCDN_RATES | 199K| 36 | 4879K|00:01:48.28 | 727K| 911 | 0 | | | | | |* 45 | INDEX RANGE SCAN | PK_OZBJZFD_OQNCVDSS | 976 | 1 | 933 |00:00:00.02 | 2928 | 2 | 0 | | | | | |* 46 | INDEX UNIQUE SCAN | PK_OQNCVDSS | 9 | 1 | 4 |00:00:00.01 | 18 | 0 | 0 | | | | | -------------------------------------------------------------------------------------------------------------------------------------------- ------------------------------------------The AUTOTRACE statistics is as follows:
Statistics
----------------------------------------------------------
72 recursive calls
0 db block gets
4242325 consistent gets
13434 physical reads
0 redo size
9673175 bytes sent via SQL*Net to client
13494 bytes received via SQL*Net from client
1141 SQL*Net roundtrips to/from client
5 sorts (memory)
0 sorts (disk)
113976 rows processed
By comparing the E-rows and A-rows from the execution, it is easy to identify that the problem starts from the operation id 25 and 26, where E-rows=1 and A-rows=1839 and 1894.
|* 25 | TABLE ACCESS BY INDEX ROWID | OZBJZFD_OQNCVDSS | 1 | 1 | 1839 |00:00:00.07 | ... |* 26 | INDEX RANGE SCAN | PK_OZBJZFD_OQNCVDSS | 1 | 1 | 1894 |00:00:00.01 | ...With E-rows=1, Oracle CBO decides to use "MERGE JOIN CARTESIAN". Notice at the end, CBO estimate only 1 row whereas actual number of rows is 113K. So the key to tune this query is to avoid the Cartesian join at operation id 5 and 6. I modified the query by adding the following hints and of course make sure the tables order is correct in the FROM clause:
/*+ ordered use_hash(E), use_hash(F) */
Here is the execution plan of the modified query:
--------------------------------------------------------------------------------------------------------------------- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | --------------------------------------------------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 1 | 2841 | 74 (9)| 00:00:01 | | 1 | SORT ORDER BY | | 1 | 2841 | 74 (9)| 00:00:01 | | 2 | HASH UNIQUE | | 1 | 2841 | 73 (7)| 00:00:01 | |* 3 | FILTER | | | | | | |* 4 | HASH JOIN OUTER | | 1 | 2841 | 72 (6)| 00:00:01 | | 5 | NESTED LOOPS | | 1 | 2835 | 68 (5)| 00:00:01 | | 6 | NESTED LOOPS | | 1 | 2828 | 67 (5)| 00:00:01 | |* 7 | HASH JOIN | | 1 | 2813 | 66 (5)| 00:00:01 | | 8 | NESTED LOOPS | | 1 | 2801 | 64 (5)| 00:00:01 | | 9 | NESTED LOOPS | | 1 | 2781 | 63 (5)| 00:00:01 | |* 10 | HASH JOIN OUTER | | 1 | 2682 | 17 (18)| 00:00:01 | | 11 | NESTED LOOPS | | 1 | 578 | 11 (0)| 00:00:01 | | 12 | NESTED LOOPS | | 1 | 326 | 10 (0)| 00:00:01 | | 13 | MERGE JOIN CARTESIAN | | 1 | 263 | 7 (0)| 00:00:01 | | 14 | NESTED LOOPS | | 1 | 153 | 5 (0)| 00:00:01 | | 15 | NESTED LOOPS | | 1 | 125 | 3 (0)| 00:00:01 | | 16 | TABLE ACCESS BY INDEX ROWID| OZBJZFDS | 1 | 120 | 2 (0)| 00:00:01 | |* 17 | INDEX UNIQUE SCAN | PK_OZBJZFDS | 1 | | 1 (0)| 00:00:01 | | 18 | TABLE ACCESS BY INDEX ROWID| OZBJZFD_CATEGORY | 1 | 5 | 1 (0)| 00:00:01 | |* 19 | INDEX UNIQUE SCAN | PK_OZBJZFD_CATEGORY | 1 | | 0 (0)| 00:00:01 | |* 20 | TABLE ACCESS BY INDEX ROWID | OZBJZFD_MARKETS | 1 | 28 | 2 (0)| 00:00:01 | |* 21 | INDEX RANGE SCAN | PK_OZBJZFD_MARKETS | 1 | | 1 (0)| 00:00:01 | | 22 | BUFFER SORT | | 1 | 110 | 5 (0)| 00:00:01 | |* 23 | TABLE ACCESS BY INDEX ROWID | MARKETS | 1 | 110 | 2 (0)| 00:00:01 | |* 24 | INDEX RANGE SCAN | PK_MARKETS | 1 | | 1 (0)| 00:00:01 | |* 25 | TABLE ACCESS BY INDEX ROWID | OZBJZFD_OQNCVDSS | 1 | 63 | 3 (0)| 00:00:01 | |* 26 | INDEX RANGE SCAN | PK_OZBJZFD_OQNCVDSS | 1 | | 2 (0)| 00:00:01 | |* 27 | TABLE ACCESS BY INDEX ROWID | OQNCVDSS | 1 | 252 | 1 (0)| 00:00:01 | |* 28 | INDEX UNIQUE SCAN | PK_OQNCVDSS | 1 | | 0 (0)| 00:00:01 | | 29 | VIEW | | 29 | 61016 | 5 (40)| 00:00:01 | | 30 | SORT UNIQUE | | 29 | 1138 | 5 (80)| 00:00:01 | | 31 | UNION-ALL | | | | | | | 32 | INDEX FULL SCAN | PK_SOURCE_TARGET_RULES | 20 | 760 | 1 (0)| 00:00:01 | | 33 | TABLE ACCESS FULL | CARRYOVER_ISOC_MAPPING | 9 | 378 | 2 (0)| 00:00:01 | |* 34 | TABLE ACCESS BY INDEX ROWID | UHCDN_RATES | 21 | 2079 | 46 (0)| 00:00:01 | |* 35 | INDEX RANGE SCAN | PK_UHCDN_RATES | 72 | | 2 (0)| 00:00:01 | | 36 | TABLE ACCESS BY INDEX ROWID | OQNCVDS_TYPES | 1 | 20 | 1 (0)| 00:00:01 | |* 37 | INDEX UNIQUE SCAN | PK_OQNCVDS_TYPES | 1 | | 0 (0)| 00:00:01 | | 38 | TABLE ACCESS FULL | BILLING_FREQ | 8 | 96 | 2 (0)| 00:00:01 | | 39 | TABLE ACCESS BY INDEX ROWID | UNIT_TYPES | 1 | 15 | 1 (0)| 00:00:01 | |* 40 | INDEX UNIQUE SCAN | PK_UNIT_TYPES | 1 | | 0 (0)| 00:00:01 | | 41 | TABLE ACCESS BY INDEX ROWID | SPEED_CODES | 1 | 7 | 1 (0)| 00:00:01 | |* 42 | INDEX UNIQUE SCAN | PK_SPEED_CODES | 1 | | 0 (0)| 00:00:01 | | 43 | INDEX FAST FULL SCAN | PK_OFFER_PROD | 1255 | 7530 | 3 (0)| 00:00:01 | |* 44 | INDEX RANGE SCAN | PK_OZBJZFD_OQNCVDSS | 1 | 12 | 3 (0)| 00:00:01 | |* 45 | INDEX UNIQUE SCAN | PK_OQNCVDSS | 1 | 6 | 1 (0)| 00:00:01 | ---------------------------------------------------------------------------------------------------------------------AUTOTRACE statistics of the modified query is also shown below:
Statistics
----------------------------------------------------------
0 recursive calls
0 db block gets
479315 consistent gets
2097 physical reads
0 redo size
9673175 bytes sent via SQL*Net to client
13535 bytes received via SQL*Net from client
1141 SQL*Net roundtrips to/from client
3 sorts (memory)
0 sorts (disk)
113976 rows processed
It can be seen that after tunning the "consistent gets" drop to 479,315 from 4,242,325.
In the production database, I created a SQL Profile to enforce the better plan.